第三章嵌入式指令集系统与程序设计
3.1 ARM 指令集及应用
ARM 指令集是理解飞腾派嵌入式开发的核心基础,它不仅决定了处理器底层如何执行程序,还直接影响系统的性能、代码密度和能效比。本节将从指令集概述入手,逐步展开 ARM 指令集的分类、特点、执行机制以及应用场景,帮助读者建立起完整的知识体系。
3.1.1 指令集概述
ARM 处理器在长期发展中形成了多种指令集体系,以满足不同应用对性能、代码密度、功耗的需求。
3.1.1.1 ARM 处理器指令集分类
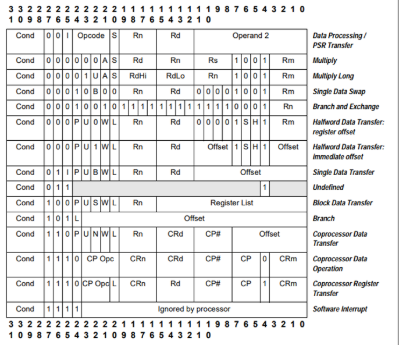
(1)ARM 指令集
- 定义与特征:
ARM 指令集是 ARM 架构的核心指令集,每条指令固定为 32 位,采用精简指令集(RISC)设计。 - 应用特点:
- 功能全面,支持复杂寻址方式和运算指令。
- 异常与中断处理必须进入 ARM 状态,确保执行的稳定性和完整性。
- 在系统启动和内核级关键任务中,通常运行在 ARM 状态,以保证最高的处理能力。
-
应用场景: 操作系统内核、驱动程序、中断服务例程。
(2)Thumb 指令集
- 定义与特征:
Thumb 指令集是一种压缩型指令集,最初所有指令均为 16 位,在 Thumb-2 技术扩展后,支持 16 位与 32 位混合编码。 - 优势:
- 提高代码密度,可显著减少存储器占用。
- 有助于降低功耗,提升嵌入式系统能效比。
- 限制: 指令长度减半后,寻址能力和灵活性略低于 ARM 指令集。
- 应用场景: 应用层程序、存储空间受限的嵌入式系统、对能效比要求较高的产品。
(3)Jazelle 指令集
- 定义与特征:
Jazelle 是一种支持 Java 字节码直接执行的扩展指令集。 - 应用特点:
在早期广泛用于移动终端加速 Java 程序的执行,但随着 JIT(即时编译)技术和高性能处理器的发展,其应用逐渐减少。 - 应用场景: 历史上主要用于 Java ME 平台,如手机、PDA。现代系统中已较少使用。
3.1.1.2 指令类型
在 ARM 汇编语言开发中,学生会接触到三类不同层次的指令。理解它们的区别是掌握 ARM 编程的关键。
(1)机器指令(Machine Instruction)
- 定义:
由处理器硬件直接识别和执行的二进制指令,包括 ARM 和 Thumb 指令集。 - 特点:
- 是程序运行的最小执行单元。
- 由编译器或汇编器翻译生成,开发者一般通过汇编代码间接编写。
(2)伪指令(Pseudo-Instruction)
- 定义:
仅在汇编期间由汇编器处理,并不会转化为实际的机器指令。 - 作用:
- 用于描述程序结构与内存布局。
- 提供符号定义、数据分配、入口标记等功能。
-
示例:
AREA RESET, CODE, READONLY ; 定义代码段 ENTRY ; 程序入口
(3)宏指令(Macro-Instruction)
- 定义:
宏是一段可重用的程序片段,类似于 C 语言中的宏定义。 - 特点:
- 在汇编过程中被展开为多条机器指令。
- 简化重复代码编写,提升代码复用性与可读性。
-
示例:
MACRO LOADIMM $reg, $val MOV $reg, #$val MEND LOADIMM R2, 100 ; 宏展开后等价于 MOV R2, #100
3.1.2 ARM 指令的特点与架构
飞腾 FTC 核心基于 ARM 架构,其指令集延续了 ARM 的经典设计思想。理解 ARM 指令的特点和架构设计原则,对于掌握底层编程、优化系统性能以及理解飞腾派平台的嵌入式开发至关重要。
1. 精简指令集(RISC)设计思想
ARM 架构是典型的 RISC(Reduced Instruction Set Computer) 处理器。与复杂指令集(CISC)处理器相比,ARM 采用更少、更规则的指令格式,每条指令通常只执行一个简单操作。这种设计带来了以下优势:
- 单周期执行: 大多数指令可在一个时钟周期内完成,提高执行效率。
- 指令长度固定: 经典 ARM 指令为 32 位定长格式,简化了指令译码逻辑,利于硬件流水线实现。
- 高效流水线: 简单规则的指令便于指令级并行和流水线优化,从而显著提升吞吐量。
这使得 ARM 处理器非常适合嵌入式系统的实时性要求,同时也为飞腾 FTC 核心的高性能低功耗特性提供了硬件基础。
2. Load/Store 架构
ARM 采用典型的 Load/Store(加载/存储)架构:
- 寄存器为中心: 所有算术和逻辑操作只能在 通用寄存器(R0–R15) 之间进行。
- 内存访问受限: 对存储器的数据访问必须通过专用指令完成:
- 加载类指令:
LDR(加载一个字/半字/字节)、LDM(批量加载)。 - 存储类指令:
STR(存储一个字/半字/字节)、STM(批量存储)。
- 加载类指令:
这种架构的优势在于:
- 避免算术逻辑单元(ALU)直接访问存储器,减少数据通路复杂度。
- 简化指令设计和流水线调度,有利于提升执行效率。
- 批量数据传输指令(如
LDM/STM)在嵌入式场景下特别高效,常用于堆栈操作、函数调用现场保护与恢复。
3. 条件执行机制
条件执行是 ARM 指令集的一个 独特而高效 的设计。
- 条件码字段: 每条 ARM 指令的高 4 位(
bit[31:28])是条件码字段,用于判断该指令是否执行。 - 依赖 CPSR 标志位: 条件码根据 CPSR(Current Program Status Register) 中的标志位(Z、N、C、V)进行判断。
Z=1:上一次结果为零。N=1:结果为负数。C=1:产生了进位或无符号溢出。V=1:产生了有符号溢出。
-
示例:
ADDEQ R0, R1, R2 ; 当 Z=1 时执行 R0 = R1 + R2 SUBNE R3, R3, #1 ; 当 Z=0 时执行 R3 = R3 - 1 - 优势:
- 减少了传统架构中频繁使用的条件跳转(branch)指令。
- 提升了指令流水线的连续性,降低分支预测失败带来的性能损耗。
- 代码更加紧凑,适合嵌入式对存储效率的要求。
4. 指令分类
ARM 指令集功能全面,可分为以下五大类:
- 数据处理指令(Data Processing Instructions)
- 实现算术运算、逻辑运算、移位操作。
- 例如:
ADD(加法)、SUB(减法)、AND(按位与)、ORR(按位或)、MOV(数据传送)、CMP(比较)。
- 存储器访问指令(Load/Store Instructions)
- 负责内存与寄存器之间的数据传送。
- 例如:
LDR、STR、LDM、STM。
- 分支指令(Branch Instructions)
- 控制程序流程,用于跳转、调用和返回。
- 例如:
B(无条件跳转)、BL(带链接的跳转,用于函数调用)、BX(带状态切换的跳转)。
- 协处理器指令(Coprocessor Instructions)
- 用于访问外部协处理器(如浮点单元、加速模块)。
- 例如:
MRC、MCR。
- 杂项指令(Miscellaneous Instructions)
- 包括中断管理、程序状态寄存器访问等。
- 例如:
MRS(读 PSR)、MSR(写 PSR)、SWI(软件中断)。
3.1.3 ARM 寄存器组织与程序状态寄存器(CPSR)
ARM 架构的高效性不仅体现在其精简指令集上,更体现在其寄存器组织结构的合理性。飞腾 FTC 核心在设计中延续了 ARM 的寄存器架构,并针对异常处理、操作模式切换和嵌入式应用做了优化。理解寄存器组织方式以及 CPSR 的作用,是学习 ARM 指令集和掌握底层系统开发的关键。
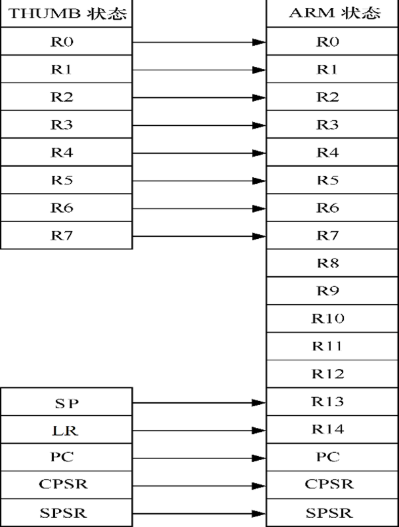
1. ARM 通用寄存器组织
ARM 处理器拥有 37 个物理寄存器,但在同一时间,只有 16 个通用寄存器(R0–R15) 和一个 程序状态寄存器(PSR) 对程序员可见。
- 通用寄存器(R0–R12):
- 用途灵活,可在算术运算、逻辑运算、数据传送等操作中使用。
- 常见约定:
R0–R3:函数参数和返回值寄存器。R4–R11:局部变量寄存器(需在函数调用时保存)。R12:通常作为临时寄存器(IP,Intra-Procedure-call scratch register)。
- 栈指针(R13,SP):
- 指向当前堆栈的栈顶,随模式不同而变化(各模式有独立的 SP)。
- 常用于函数调用现场保护、操作系统任务切换等。
- 链接寄存器(R14,LR):
- 保存函数调用或异常返回地址。
- 在
BL(带链接跳转)指令执行时自动更新。
- 程序计数器(R15,PC):
- 保存当前执行指令的地址,ARM 处理器采用流水线机制,PC 的值通常指向当前指令地址 + 8 字节。
- 在分支、异常处理时会被更新。
2. ARM 工作模式与寄存器
ARM 处理器支持多种工作模式,不同模式下部分寄存器会被独立复制(Banking),以便快速切换上下文。常见模式包括:
| 模式 | 用途 | 特点 |
|---|---|---|
| User(用户模式) | 普通程序运行 | 仅能访问基本寄存器和用户权限。 |
| FIQ(快速中断模式) | 高速中断响应 | 独立的 R8–R14,减少中断响应保存开销。 |
| IRQ(普通中断模式) | 普通中断响应 | 独立的 SP 和 LR。 |
| Supervisor(管理模式) | 操作系统管理 | 常用于操作系统内核。 |
| Abort(终止模式) | 存储器访问异常 | 用于处理数据访问错误。 |
| Undefined(未定义模式) | 处理非法指令 | 通常进入异常处理程序。 |
| System(系统模式) | 特权级执行 | 与用户模式寄存器相同,但具备特权权限。 |
📌 寄存器优势: 通过为中断模式和异常模式配置独立的栈指针(SP)和返回地址寄存器(LR),ARM 能在中断触发时避免频繁的现场保存操作,从而显著缩短响应时间,这在实时嵌入式系统中尤为重要。
3. 程序状态寄存器(PSR)
ARM 处理器提供三个状态寄存器:
- CPSR(Current Program Status Register,当前程序状态寄存器)
- 当前可见状态寄存器,保存条件标志位、控制位和当前工作模式信息。
- 关键位说明:
- 条件标志位(bit[31:28]):
N:负数标志Z:零标志C:进位标志V:溢出标志
- 控制位:
I:IRQ 中断屏蔽位F:FIQ 中断屏蔽位T:处理器状态位(0=ARM 状态,1=Thumb 状态)
- 模式位(bit[4:0]): 决定当前处理器工作模式(如 User、FIQ、IRQ 等)。
- 条件标志位(bit[31:28]):
- SPSR(Saved Program Status Register,保存的程序状态寄存器)
- 在异常或中断发生时,CPSR 的内容会自动保存到对应模式下的 SPSR 中。
- 异常处理完成后,可通过
MOVS或SUBS等指令恢复原状态。
4. CPSR 在条件执行与异常处理中的作用
- 条件执行:
- CPSR 的
N/Z/C/V标志直接影响 ARM 指令的条件执行。 - 例如,
BEQ(等于时分支)依赖于Z=1。
- CPSR 的
- 模式切换:
- 当中断触发时,CPSR 的模式位会自动切换,进入对应的中断模式。
- 此时,CPSR 会保存到 SPSR,以便中断返回时恢复。
- 状态切换:
- 通过修改 CPSR 中的
T位,可以在 ARM 指令集和 Thumb 指令集之间切换。
- 通过修改 CPSR 中的
3.1.3 ARM 指令寻址方式
寻址方式(Addressing Mode)是处理器在执行指令时,如何获取操作数或操作数地址的规则。 对嵌入式系统开发者而言,理解寻址方式不仅是编写汇编程序的基础,也是优化性能和存储资源的重要手段。
ARM 架构在保持 RISC 精简指令集高效性的同时,提供了多达 7 种寻址方式,这是其区别于其他 RISC 架构的重要特征之一。这些寻址方式在飞腾派所基于的 ARMv8-A(AArch64)/ARMv7-A 架构中均有体现,具有较强的实用性。
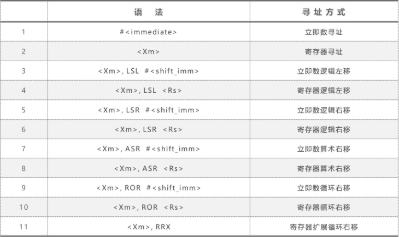
1. 核心寻址方式(非内存访问)
核心寻址方式主要在 数据处理指令(如加法、逻辑运算)中使用,操作数来源于立即数或寄存器。
| 序号 | 寻址方式 | 描述 | 示例 | 应用场景 |
|---|---|---|---|---|
| 1 | 立即寻址 (Immediate) | 操作数是一个常数,直接在指令中给出(以 # 表示)。 |
ADD R0, R1, #5 |
把 R1 的值加上常数 5,结果存入 R0。常用于简单数值操作。 |
| 2 | 寄存器寻址 (Register) | 操作数位于寄存器中,指令直接读取寄存器内容。 | ADD R0, R1, R2 |
把 R1 与 R2 相加,结果存入 R0。适合频繁数据操作。 |
📌 开发提示: 寄存器寻址是最快速的方式,因为操作数已经在 CPU 内部,无需访问内存。这是编写高效代码的首要策略。
2. 内存访问寻址方式(Load/Store 架构核心)
ARM 采用 Load/Store 架构,所有内存访问必须通过特定指令完成。有效地址通常由 基址寄存器 + 偏移量 构成。
| 序号 | 寻址方式 | 描述 | 示例 | 应用场景 |
|---|---|---|---|---|
| 3 | 寄存器间接寻址 (Register Indirect) | 基址寄存器的内容即为有效地址。 | LDR R0, [R1] |
把 R1 指向的内存内容读到 R0。常用于指针访问。 |
| 4 | 基址变址寻址 (Base + Offset) | 有效地址 = 基址寄存器内容 + 偏移量(立即数或寄存器)。 | LDR R0, [R1, #4] |
读取地址 (R1+4) 的内容。常用于访问数组元素或结构体字段。 |
基址变址寻址的自动索引扩展:
- 前索引(Pre-indexed, 带写回):
- 地址 =
基址 + 偏移→ 内存访问 → 新地址写回基址。 - 例:
LDR R0, [R1, #4]!
- 地址 =
- 后索引(Post-indexed):
- 地址 = 基址 → 内存访问 →
(基址 + 偏移)写回基址。 - 例:
LDR R0, [R1], #4
- 地址 = 基址 → 内存访问 →
3. 高级寻址方式
ARM 提供了几种高级寻址方式,以减少指令条数、提高执行效率。
| 序号 | 寻址方式 | 描述 | 示例 | 应用场景 |
|---|---|---|---|---|
| 5 | 多寄存器寻址 (Multiple Register Transfer) | 一条指令可批量操作多个寄存器(最多 16 个)。 | STMIA R1!, {R0-R7} |
将 R0–R7 的内容依次写入以 R1 为起始地址的内存,并更新 R1。常用于函数调用保存现场。 |
| 6 | 寄存器移位寻址 (Register Shift) | 在运算前对操作数进行移位(LSL, LSR, ASR, ROR)。 | ADD R0, R1, R2, LSL #2 |
R2 左移两位后与 R1 相加,结果写入 R0。常用于数组索引(乘以字长)。 |
| 7 | 相对寻址 (PC-Relative) | 有效地址 = PC 值 + 偏移量。 | B Label |
程序跳转,常用于分支、子程序调用,实现位置无关代码(PIC)。 |
ARM 的寻址方式兼顾了 简洁性(RISC 思想) 和 灵活性(高效批量操作):
- 对应用层程序员:重点掌握 立即寻址、寄存器寻址、基址变址寻址。
- 对底层开发者(驱动/内核):必须熟悉 自动索引、多寄存器寻址、PC 相对寻址 等高级模式,才能写出高效可靠的底层代码。
3.2 Thumb 指令集及应用
Thumb 指令集是 ARM 架构为嵌入式场景提出的一套压缩指令编码方案,目标是提高代码密度并改善内存/缓存利用效率。作为嵌入式软硬件开发者,应既理解 Thumb 的设计动机与实现机制,也掌握在工程中如何合理选择与混合使用 ARM / Thumb(或在现代 AArch64 环境中理解其意义)。
3.2.1 Thumb 的设计目标与主要特性
- 高代码密度:早期 Thumb 指令均为 16 位,能显著减少可执行二进制体积,降低 Flash 与 I-cache 压力。
- 解码与执行:Thumb 指令在取出后会被译码/解压为内部等效的 32 位微指令(或在后端以 32 位语义执行),因此能在牺牲一点解码开销的前提下换取更高的缓存/存储利用率。
- Thumb-2(混合编码):Thumb-2 引入了 32 位扩展指令,使得 Thumb 状态中可以混合 16 位和 32 位指令,从而在代码密度与表达能力之间取得更好平衡。现代 Cortex-A 系列广泛支持 Thumb-2。
- 兼容性与互操作(Interworking):ARM 提供状态切换机制(BX/BLX 等)使 ARM 与 Thumb 代码可以互相调用(称为 interworking)。编译器和链接器通常负责生成正确的入口地址和修饰位。
3.2.2 Thumb-1 vs Thumb-2:编码与能力比较
- Thumb-1(原始 Thumb):
- 指令长度固定为 16 位,表达能力受限(立即数/寄存器范围较小)。
- 更高的代码密度,但对复杂操作(如广泛立即数、复杂寻址、浮点)支持弱。
- Thumb-2:
- 支持 16 位与 32 位混合指令,32 位指令用于表达更复杂操作(长立即量、复杂寻址、条件执行替代方案等)。
- 保持整体较高密度的同时,接近 ARM 指令集的表达能力与性能。
- 工程意义:在现代 A-class(应用级)核中,大多数编译器选择 Thumb-2 作为默认的 Thumb 模式,因为它在密度与性能之间更优。
3.2.3 条件执行:IT(If-Then)与 ARM 条件域的差异
- ARM(AArch32 的 ARM 模式):每条指令有 4-bit 的条件码字段(16 种条件),几乎任意指令都可带条件执行(例如
ADDEQ)。 - Thumb:
- 原始 Thumb(16-bit)没有条件域,对条件则大量依赖分支指令。
- Thumb-2 引入
IT指令(If-Then),允许对接下来的最多 4 条指令规定条件执行掩码(例如ITTE NE),从而在 Thumb 模式下也能实现短序列的条件执行,减少分支开销。
- 要点:
IT指令本身有严格的语义:只能在 Thumb 状态下使用,并且不能跨基本块(不能在中间插入分支或函数调用改变控制流)。- 在性能敏感的路径上,Thumb 下尽量使用
IT或显式条件跳转来平衡指令密度与流水线连续性。
4.2.4 ARM / Thumb 的互操作(Interworking)与状态切换机制
- BX / BLX 指令:
BX <reg>:分支并交换状态。目标地址最低位LSB用于指示进入 ARM(LSB=0)或 Thumb(LSB=1)状态。BLX <reg>:带链接的分支并交换状态(用于函数调用并保存返回地址)。
- 函数指针与 LSB 规则:函数入口地址的最低位被用作状态标记(AArch32)。例如,将函数指针的 LSB 置 1 表示该指针指向 Thumb 函数。编译器/链接器与运行时在 interworking 时自动维护这一约定。
-
C 代码中若需要人工构造可调用地址,可使用:
void (*fp)(void) = (void (*)(void))((uintptr_t)addr | 1); // 强制 Thumb -
注意:仅在 AArch32(32-bit)环境适用;在 AArch64 环境没有此约定(AArch64 不使用 Thumb 状态)。
-
- 汇编中的切换指示:
- GNU as 可用
.thumb/.arm指示切换当前汇编模式;使用.thumb_func标注函数。 - 链接时函数符号的最低位可能被工具链操作以提供 interworking 支持。
- GNU as 可用
4.2.5 编译器/工具链支持与常用选项
- GCC / Clang 常用选项:
-mthumb:生成 Thumb 指令(Thumb-2 若目标 CPU 支持)。-marm:生成 ARM 指令。-march=/-mcpu=:指定目标架构/处理器(例:-mcpu=cortex-m4、-march=armv7-a),以使编译器生成最优指令并启用相应扩展。-mfloat-abi=、-mfpu=:控制浮点 ABI 和 FPU 类型(在 Thumb-2 使用浮点时常用)。
- 在源文件层面强制 Thumb:
-
汇编文件中可用:
.thumb .thumb_func my_thumb_func: ... .arm -
C 层可通过单文件编译选项(
-mthumb)或使用函数级属性(部分编译器/版本支持__attribute__((target("thumb"))),但便携性需验证)。
-
- 检查生成代码:使用
objdump -d -M reg-names=arm或arm-none-eabi-objdump检查是否生成 Thumb 指令(反汇编显示 16/32-bit encodings)。
4.2.6 性能与代码密度的权衡
- 代码密度的好处:
- 降低 Flash 占用;在小存储设备上尤为重要。
- 更高 I-cache 命中率 → 实际运行吞吐常常更好,尤其是对内存带宽敏感的系统。
- 开销与限制:
- 译码开销:Thumb(尤其 Thumb-2)有额外的解码步骤,可能带来微小的延迟。
- 表达能力:较短的 16 位编码导致某些操作需用多条指令实现。对于重算术或复杂寻址,ARM 模式可能更高效。
- 经验法则:
- 对控制代码/中断/启动路径选择 ARM(或在 AArch64 使用 64 位指令)。
- 对大量库代码/应用逻辑/设备驱动可优先考虑 Thumb,以优化整体内存占用与 I-cache 效率。
- 对关键性能热点(热路径)通过基准测试决定是否使用 ARM(或在 Thumb-2 中用 32-bit 指令实现)。
4.2.7 实际示例:汇编与 C 混合、状态切换
示例 A:用 GNU 汇编写 Thumb 函数并导出给 C 调用
文件 thumb_func.S:
.syntax unified
.thumb @ 切换到 Thumb 模式
.thumb_func
.global thumb_add
thumb_add:
push {r4, lr} @ 保存 callee-saved and lr
add r0, r0, r1 @ r0 = r0 + r1
pop {r4, pc} @ 恢复并返回
对应 C 调用:
extern int thumb_add(int a, int b);
int foo(void) {
return thumb_add(3,4); // 编译时链接器会处理 interworking
}
编译:
arm-none-eabi-gcc -mcpu=cortex-m3 -mthumb -c thumb_func.S
arm-none-eabi-gcc -mcpu=cortex-m3 -mthumb -c main.c
arm-none-eabi-gcc -mcpu=cortex-m3 -mthumb thumb_func.o main.o -o app.elf
示例 B:在运行时根据地址 LSB 切换状态并调用
#include <stdint.h>
typedef void (*func_t)(void);
void call_thumb(void *addr) {
// 强制 LSB = 1 表示 Thumb
func_t f = (func_t)((uintptr_t)addr | 1);
f();
}
注意:仅在 AArch32 下有效;在 AArch64 该写法不适用。
4.2.8 调试、陷阱与注意事项
- 断点与调试器:某些调试器设置断点时需要知道当前指令集状态(ARM/Thumb),否则断点地址计算会错位。使用支持 interworking 的工具链(OpenOCD+GDB)时通常自动处理。
- 对齐要求:Thumb 16-bit 指令需要半字(2 字节)对齐;Thumb-2 32-bit 指令需要字(4 字节)对齐。务必检查链接器脚本和汇编
.align。 - 函数指针上下位:不要随意在 AArch64 环境使用 LSB trick;在跨架构(AArch64 ↔ AArch32)场景下 interworking 有更复杂的限制(通常使用 EL1/EL0 与 AArch32 compatibility layer),工程中应避免混淆。
- 中断/异常路径:启动代码与异常处理应优先使用 ARM/AArch64 模式,以避免 Thumb 的解码延迟或不支持的原语影响实时性。
推荐实践与教学实验
最佳实践:
- 在项目启动阶段定义策略:哪些模块默认编译为 Thumb,哪些为 ARM(或在 AArch64 中全部使用 AArch64 指令)。
- 在 makefile 中通过
-mthumb/-marm或对单文件设定编译标志,便于控制与测试。 - 使用性能分析(cycle counter、perf、profiling)来决定热点是否需要降级为 ARM。
- 保持汇编函数最小化,尽可能让编译器负责指令选择(编译器通常能生成更优的 Thumb-2 代码)。
实验建议:
- 使用飞腾派或仿真器:分别编译一个较大算法(例如矩阵乘法)为 ARM 与 Thumb-2,比较 binary size、I-cache miss 和 运行时间。
- 实现一个混合项目:中断和启动代码用 ARM,实现关键中断延迟测试;其余应用代码用 Thumb。测量中断响应延迟并对比纯 Thumb 的结果。
- 观察
objdump -d输出,识别 16-bit 与 32-bit Thumb 指令编码(指令字节长度不同),练习理解汇编生成结果。
小结:
- Thumb(尤其 Thumb-2)为嵌入式开发提供了性价比极高的指令集选择:在保持较强表达能力的同时,显著提升代码密度。
- 在飞腾派(及一般 ARM 平台)上,合理混合 ARM / Thumb 能在性能与存储占用之间取得最佳折中:启动/中断/内核优先使用 ARM(或 AArch64);应用层、库和大体积代码优先考虑 Thumb/Thumb-2。
- 理解 interworking、IT 指令、编译器选项和调试陷阱对完成稳定、高效的底层软件至关重要。
3.3 ARM汇编语言及程序设计
ARM 汇编语言是嵌入式开发中最接近硬件的一种编程方式。它允许开发者直接操作寄存器、内存和指令,从而获得对底层系统的精确控制。本节将以飞腾派平台为基础,系统介绍 ARM 汇编语言的基本文件结构、伪操作的使用方法以及程序段的组织方式,并结合实际示例帮助读者建立对裸机编程和嵌入式启动代码的理解。
3.3.1 汇编语言文件格式与结构
ARM 汇编语言的源代码文件通常以 .s 或 .S 为扩展名。其中 .s 文件直接被汇编器识别,而 .S 文件则会先经过预处理器(可支持宏定义、条件编译)再交由汇编器处理。
一份 ARM 汇编源文件一般包含以下几部分:
- 标号(Label)
- 用于标识程序中的某个位置或变量地址。
- 必须顶格书写,后面加冒号
:。 -
示例:
Loop: ADD R0, R0, #1 ; 循环计数
- 指令(Instruction)与伪操作(Directive)
- 指令由处理器执行,例如
MOV、LDR、STR。 - 伪操作由汇编器处理,用于定义段、数据或符号,例如
AREA、ENTRY、DCD。 -
示例:
MOV R0, #0xFF ; 将立即数 0xFF 装入 R0 DCD 0x12345678 ; 定义一个 32 位常量
- 指令由处理器执行,例如
- 注释(Comment)
- 使用分号
;开始,解释代码含义或用途。 -
示例:
LDR R1, =0x40000000 ; 加载外设寄存器基地址
- 使用分号
- 程序结尾(END)
- 每个汇编源文件必须以
END结束,标识源程序终止。
- 每个汇编源文件必须以
3.3.2 汇编语言伪操作
伪操作在 ARM 汇编编程中扮演着极其重要的角色,它们控制程序的布局和符号可见性。飞腾派平台上的裸机开发尤其依赖伪操作来组织启动代码和中断向量表。
常用伪操作如下表所示:
| 伪操作 | 功能 | 应用场景 |
|---|---|---|
AREA |
定义一个代码段或数据段,并指定其属性(CODE/DATA、READONLY/READWRITE)。 | .text 代码段、.data 数据段的声明 |
ENTRY |
声明程序入口点。 | 启动代码的第一条指令 |
EXPORT |
声明一个符号为全局可见。 | 汇编函数被 C 语言调用 |
IMPORT |
引用外部符号(来自其他文件)。 | 汇编调用 C 语言函数 |
DCD |
定义 32 位常量数据。 | 向量表、常量表 |
DCB |
定义 8 位数据。 | 定义字符串或字节数组 |
SPACE |
预留指定字节的存储空间。 | 定义缓冲区 |
ALIGN |
数据对齐。 | 确保变量按字长边界存放 |
END |
标识源文件结束。 | 所有汇编文件必须使用 |
示例:中断向量表的定义
AREA RESET, CODE, READONLY
ENTRY
EXPORT __Reset_Handler
__Vectors
DCD __Reset_Handler ; 复位中断
DCD NMI_Handler ; NMI 中断
DCD HardFault_Handler ; 硬错误中断
; 其余中断向量略
3.3.3 程序段的组织
ARM 汇编程序通过程序段(Section)来组织和管理代码与数据。这些段最终会在链接脚本的控制下映射到物理内存空间中。
- 代码段(.text)
- 保存可执行指令。
- 通常设置为
READONLY,防止运行时被意外修改。 -
示例:
AREA MyCode, CODE, READONLY
- 已初始化数据段(.data)
- 存放定义时已赋值的全局变量和常量字符串。
- 链接时会被放置到 Flash/ROM,但启动代码会在上电时复制到 RAM。
- 未初始化数据段(.bss)
- 存放未显式初始化的全局变量或静态变量。
- 不占用 Flash 空间,仅在 RAM 中分配空间,启动时需要清零。
- 常量数据段(.rodata)
- 存放只读常量数据,例如查找表或常量字符串。
示例:组织一个简单程序段
AREA InitData, DATA, READWRITE
var1 DCD 0x1234 ; 已初始化数据
buffer SPACE 64 ; 缓冲区(未初始化)
AREA MyCode, CODE, READONLY
ENTRY
EXPORT __Reset_Handler
__Reset_Handler
LDR R0, =var1 ; 取 var1 地址
LDR R1, [R0] ; 加载 var1 的值
ADD R1, R1, #1
STR R1, [R0] ; var1++
B . ; 无限循环
END
3.4 嵌入式 C 语言编程简介
在飞腾派这类复杂的嵌入式系统中,C 语言是最核心的开发语言。底层启动和少量关键初始化由汇编语言实现,而驱动程序、操作系统内核乃至大部分应用逻辑,均采用 C 语言编写。C 语言既贴近硬件,又具有较高的抽象性,既能直接操作寄存器与地址,又能通过模块化和结构化方法实现复杂的软件系统。
在嵌入式开发中,统一的编程规范和良好的编码习惯至关重要。这不仅关系到代码的可读性、可维护性,还直接影响到系统的可靠性、安全性和移植性。
3.4.1 编码规范与风格
一致的编码风格能让团队开发协作更加高效,减少因风格不统一带来的理解成本。
- 缩进风格
- 推荐采用 4 个空格缩进,禁止混用空格和 Tab。
- 所有语句块(函数体、循环体、条件体)必须缩进,反映层次关系。
-
示例:
if (status == OK) { InitDevice(); StartTimer(); }
- 代码行宽
- 每行不超过 80–100 个字符。
- 超长表达式分行时,应在逻辑点(如运算符、逗号)处换行。
-
示例:
config_value = ConfigureDevice(device_id, timeout_ms, buffer_size);
- 块分界符(大括号)
- 推荐采用 K\&R 风格(左大括号与语句同行),保证与大多数开源项目一致。
-
示例:
for (i = 0; i < MAX_SIZE; i++) { buffer[i] = 0; }
3.4.2 命名规则
清晰的命名是“自解释代码”的关键,让代码在没有额外注释时依然容易理解。
- 简明达意原则
- 名称要能准确反映变量/函数用途。
- 推荐:
buffer_size,而不是bs。
- 命名习惯
- 宏与常量: 全大写 + 下划线,例
MAX_BUFFER_SIZE。 - 函数: 驼峰命名,首字母大写,例
InitDevice()。 - 变量: 小写 + 下划线,例
sensor_value。 - 结构体/枚举: 驼峰命名或带
_t后缀,例typedef struct { ... } device_config_t;。
- 宏与常量: 全大写 + 下划线,例
- 避免单字符命名
- 除了循环计数器
i, j, k等局部变量,禁止使用无意义的单字符变量名。
- 除了循环计数器
3.4.3 注释规范
注释应解释 为什么这样写,而不是仅仅翻译代码。
- 文件头注释
- 每个 C 文件必须包含文件说明、作者、日期、功能简述。
-
示例:
/** * @file uart_driver.c * @brief UART 驱动实现文件,适配飞腾派硬件平台 * @author XXX * @date 2025-09-26 */
- 函数注释
- 每个函数在声明或定义前必须写明输入参数、返回值和功能描述。
-
示例:
/** * @brief 初始化 UART 外设 * @param baud_rate 波特率 * @return 0 成功,非 0 失败 */ int UartInit(int baud_rate);
- 行内注释
- 用
//解释复杂逻辑或特殊处理。 - 推荐放在代码右侧或上一行。
- 用
3.4.4 模块化与可移植性
飞腾派的嵌入式开发强调代码的可重用性与移植性。良好的模块化设计是实现这一目标的基础。
- 头文件与源文件分离
- 头文件 (
.h) 用于声明接口和宏定义;源文件 (.c) 用于实现功能。 - 示例:
uart.h:声明UartInit()、UartSend()等接口uart.c:实现上述函数
- 头文件 (
- 硬件抽象层(HAL)
- 封装硬件相关寄存器访问,避免在应用层直接操作寄存器。
-
示例:
// HAL 层函数 void HalUartWriteReg(uint32_t addr, uint32_t value);
- 条件编译与平台适配
- 使用
#ifdef宏定义区分平台。 -
示例:
#ifdef FT_ARMV8 // 飞腾派平台特有寄存器 #endif
- 使用
3.4.5 编译与调试习惯
在嵌入式开发中,调试通常比编写代码更耗时,良好的调试习惯能极大提高效率。
- 逐步构建与测试
- 每次仅修改一小部分代码,并在硬件上快速验证。
- 避免一次性写入大量未测试代码。
- 日志输出
- 在裸机开发中可通过 UART 输出调试信息。
-
建议编写统一的调试宏:
#define DEBUG_PRINT(fmt, ...) printf("[DEBUG] " fmt, ##__VA_ARGS__)
- 断言与错误处理
- 使用
assert()或自定义断言宏,及时捕获错误。
- 使用
3.4.3 版本控制
在嵌入式项目中,良好的注释习惯和专业的版本管理(以 Git 为主流)是保证长期可维护性、协作效率与发布可追溯性的基石。本节给出详细规范、实战建议与工具/命令示例,适用于飞腾派这类复杂嵌入式平台开发。 您提了一个非常基础但又极其重要的问题:为什么需要版本控制?
1. 为什么使用 Git
对于嵌入式开发,特别是基于飞腾派这种复杂的软硬件协同项目来说,版本控制系统(Version Control System, VCS),尤其是 Git,是不可或缺的基石。它的作用远不止于备份文件,而是彻底改变了团队协作和项目管理的方式。
版本控制的五大核心价值
- 完整的历史记录与“后悔药” 版本控制系统最直接的作用就是追踪每一次修改。
- 时间机器: VCS 会记录项目文件在何时、何人、何地、为何进行了哪些改动。它为您的项目建立了一个完整的、可追溯的时间轴。
- 安全网(回滚): 无论您犯了多大的错误,版本控制系统都能让您随时回到项目历史上的任何一个稳定状态。例如,如果您在飞腾派的驱动代码中引入了一个致命的 Bug,您可以一键回滚到前一个没有 Bug 的版本,就像服用了“后悔药”。
- 审计与分析: 当一个 Bug 出现时,您可以精确地查看到是哪一行代码、由谁引入的,帮助您快速定位问题。
- 高效的团队协作
版本控制是团队并行开发的基础工具,它解决了多人同时修改代码的冲突问题。
- 并行工作: 每个开发者可以在自己的**分支(Branch)**上独立工作,修改自己的代码,而不会干扰主项目或其他人的进度。这在嵌入式项目中尤为重要,例如一人负责 CAN 驱动,另一人负责应用逻辑。
- 冲突管理: 当多名开发者都修改了同一文件时,VCS 能够识别这些冲突(Conflict),并提供工具让开发者以结构化的方式解决这些冲突,将各方的修改整合到一起。
- 代码集成: 通过 **合并(Merge)或变基(Rebase)**操作,可以将独立分支上的稳定功能安全、有序地集成到主线上。
- 分支管理与新功能试验
分支(Branching)机制是版本控制,特别是 Git 的精髓。
- 安全沙盒: 您可以为每一个新功能开发、每一个 Bug 修复创建一个独立的分支。这个分支就像一个安全沙盒,您可以在其中尽情试验、破坏,而不会影响到正在稳定运行的主代码(通常称为
main或master分支)。 - 版本隔离: 您可以同时维护多个项目版本,比如一个稳定版本(用于生产)和一个开发版本(用于新功能测试)。
- 自动化与持续集成/部署(CI/CD)
对于基于飞腾派的 Linux 系统项目,版本控制是实现自动化构建和部署的前提。
- 触发自动化: 每次代码提交到远程仓库后,可以自动触发**持续集成(CI)**服务器进行自动化编译、单元测试、甚至是交叉编译生成飞腾派上的可执行文件。
- 持续部署(CD): 只有通过所有自动化测试的代码,才会被系统自动部署到目标测试硬件(如飞腾派开发板)上进行测试或发布。
- 清晰的代码审查流程
版本控制工具提供清晰的差异(Diff) 视图,使代码审查(Code Review)变得高效。
- 聚焦变化: 审查者无需查看整个项目,只需查看开发者在本次提交(Commit)中新增、删除或修改了哪些具体的代码行。
- 提升质量: 确保每段进入主线的代码都经过了同行专家的审核,从而提高代码质量、减少潜在 Bug。
总之,版本控制系统是将混乱的项目迭代转化为可控、高效、高质量的软件工程的关键工具。在任何现代的嵌入式开发项目中,它都是必备技能。
2. 仓库组织建议
- 源码(/src):驱动、应用代码。
- BSP(/bsp):板级支持、设备树、启动脚本、linker scripts。
- Toolchains / CI(/ci):构建脚本、workflow,不要把交叉编译器放入 repo(参考版本号并在 CI 中下载)。
- Docs(/doc):schematic 摘要、flash layout、版本说明。
- Release artifacts:固件二进制通过 Git LFS 或 CI Release 管理,不直接提交到源码仓库。
3. .gitignore 示例
对于进行版本控制的开发者而言,.gitignore 文件是 Git 工具中一个至关重要且基础的配置文件。
它的主要作用就是:告诉 Git 应该忽略哪些文件和文件夹,不将它们纳入版本控制系统。
1. 忽略自动生成的文件和中间产物
在软件开发,尤其是嵌入式和编译型语言开发(如 C/C++)中,会产生大量由工具链自动生成的文件。这些文件不属于项目的源代码,不应该被提交到代码仓库中。
- 编译输出文件:
- 飞腾派 (Linux) 嵌入式开发: 编译生成的可执行文件(例如
a.out、my_app)、目标文件(.o文件)、依赖文件(.d文件)。 - IDE 产生的缓存文件: 各种集成开发环境(如 VS Code, Eclipse, Keil, IAR)生成的项目配置文件、索引文件、日志文件和临时文件夹(如
.vscode/,.idea/,Debug/,Release/)。
- 飞腾派 (Linux) 嵌入式开发: 编译生成的可执行文件(例如
- 运行时文件: 日志文件(
.log)、数据库文件(如 SQLite 的.db文件)、用户上传的媒体文件等。
如果没有 .gitignore: 每次编译或运行后,Git 都会检测到这些文件的变化,提示你需要提交它们。开发者必须手动忽略,非常繁琐且容易出错。
2. 忽略敏感信息和本地配置文件
为了项目的安全和可移植性,.gitignore 必须忽略包含敏感信息的文件。
- 敏感信息: 包含 API 密钥、数据库密码、第三方服务凭证等的配置文件。这些文件通常只在本地使用,不应暴露在公共仓库中。
- 本地环境配置: 包含了开发者本地路径设置、硬件配置(如飞腾派连接的串口号、IP 地址)等,这些配置在其他开发者的机器上是无效的。
作用: 确保每个开发者在克隆仓库后,可以安全地配置自己的本地环境,而不会将私人或敏感数据泄露给团队其他成员或公共仓库。
3. 保持仓库干净和高效
- 减小仓库体积: 忽略大型的中间文件(如编译产物、编译库),可以显著减小 Git 仓库的体积,加快克隆(Clone)、拉取(Pull)和推送(Push)的速度。
- 聚焦核心代码: 确保版本历史(History)只记录项目源代码和配置文件的有效变化,使代码审查和回溯历史记录更加清晰和高效。
在一个基于飞腾派的嵌入式 Linux 项目中,一个典型的 .gitignore 文件可能包含以下内容:
# 编译输出和目标文件
############################
*.o # 目标文件
*.d # 依赖文件
*.elf # 最终的 ELF 可执行文件
*.bin # 最终的二进制固件文件
*.hex # Hex 文件
a.out # 默认可执行文件名
# 操作系统临时文件
############################
.DS_Store # macOS 自动生成的文件
*~ # Linux 临时备份文件
# IDE 和工具链目录
############################
/Debug # 调试版本目录
/Release # 发布版本目录
.vscode/ # Visual Studio Code 项目配置
.idea/ # JetBrains IDEs(如 CLion)配置
build/ # CMake 或其他构建系统生成的通用构建目录
# 敏感信息和本地配置文件
############################
config_local.h # 包含 API key 或密码的本地配置文件(不上传)
/logs/ # 日志文件目录
4. 分支策略
- 主干模型(Trunk-based):短 lived feature branches -> PR -> CI green -> 合入 main,适合频繁集成与 CI 驱动团队。
- 或 Git Flow(小团队/发布控制):
main(release)/develop(日常合并)/feature/*/hotfix/*。对嵌入式大版本发布(固件)管理有用。
选择要与 CI 能力、团队规模和发布流程匹配。
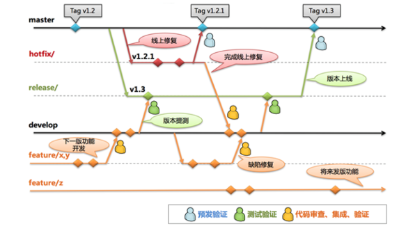
5. 提交规范(强制/建议)
-
使用 Conventional Commits 风格或类似约定(便于自动化生成 changelog):
feat(uart): add DMA based tx support - implement dma_start() - add tests for dma tx - 每个 commit 尽量原子(只做一件事),避免把多项不相关更改混为一体。
- 在提交信息里引用 issue 编号与测试结果(例如
Fixes #123 - tested on FT-Board v1)。
6. 实用 Git 命令片段(常用)
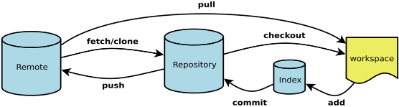
-
新建分支并推送:
git checkout -b feature/uart-dma git add . git commit -m "feat(uart): add dma tx support" git push -u origin feature/uart-dma -
创建签名 tag 并推送:
git tag -s v1.0.0 -m "v1.0.0 release" git push origin --tags -
回退(安全):
git revert <commit> -
查找引入 bug 的提交(二分法):
git bisect start git bisect bad # 当前为坏版本 git bisect good <hash> # 已知好版本 # git bisect run ./test_script.sh -
cherry-pick:
git cherry-pick <commit>
3.5 嵌入式 C 与 ARM 汇编语言混合编程
本节内容详细阐述了在飞腾派裸机开发环境下,C 语言与 ARM 汇编语言如何协作,特别强调堆栈管理、寄存器使用和函数调用的规范流程,为高效混合编程提供全面指导。
3.5.1 过程调用标准(AAPCS/ATPCS)
1. 标准概述
- ATPCS(ARM Thumb Procedure Call Standard):早期 Thumb 指令集下的函数调用规范。
- AAPCS(ARM Architecture Procedure Call Standard):当前 ARM 官方通用标准,适用于 32 位和 64 位 ARM 架构(包括 AArch32/AArch64)。
2. 核心目的
- 定义参数传递方式(寄存器/堆栈)。
- 指定返回值寄存器。
- 规定寄存器保存策略(调用者与被调用者责任划分)。
- 确保 C 语言生成代码与手写汇编函数接口一致,实现二进制兼容。
3.5.2 寄存器使用规则(AAPCS 核心)
1. 通用寄存器(R0-R12)
| 寄存器 | 别名 | 功能 | 保持规则 |
|---|---|---|---|
| R0-R3 | A1-A4 | 前四个参数 / 返回值 | 调用者保存:函数返回后内容不可保证,调用者若需保留需入栈 |
| R4-R11 | V1-V8 | 局部变量 | 被调用者保存:函数必须恢复原值 |
| R12 | IP | 临时寄存器/中转 | 无需恢复,函数可临时使用 |
2. 特殊寄存器
| 寄存器 | 别名 | 功能 | 规则 |
|---|---|---|---|
| R13 | SP | 堆栈指针 | 必须在函数返回时保持平衡(入栈/出栈对称) |
| R14 | LR | 链接寄存器 | 保存返回地址,返回前需恢复或跳转到 PC |
| R15 | PC | 程序计数器 | 直接读写会导致跳转,谨慎使用 |
3.5.3 混合编程调用流程
1. C 语言调用汇编函数
- 参数传递:C 编译器将前 4 个参数放入 R0-R3。
- 函数入口:
-
若使用 R4-R11 或调用其他函数,需 入栈保存现场:
STMDB SP!, {R4-R11, LR} ; 保存调用者寄存器和返回地址
-
- 函数执行:通过 R0-R3 访问参数,执行核心逻辑。
- 函数出口:
-
恢复现场:
LDMIA SP!, {R4-R11, PC} ; 出栈并返回 -
返回值:放入 R0,C 语言调用者自动获取。
-
2. 汇编调用 C 语言函数
- 准备参数:将前 4 个参数放入 R0-R3。
-
调用 C 函数:使用
BL指令跳转:BL c_function - 获取返回值:C 函数返回后,R0 中包含返回值,汇编可直接使用。
3.5.5 示例:C 调用汇编函数
// C 语言函数调用汇编函数
extern int AddTwoNumbers(int a, int b);
int main(void) {
int result = AddTwoNumbers(5, 7); // R0=5, R1=7
while(1);
return 0;
}
// ARM 汇编实现
AREA MyCode, CODE, READONLY
EXPORT AddTwoNumbers
AddTwoNumbers
STMFD SP!, {R4, LR} ; 保存现场
ADD R0, R0, R1 ; R0 = R0 + R1
LDMFD SP!, {R4, PC} ; 恢复现场并返回
END
- 汇编函数正确保存和恢复了 R4(示例中未使用,可扩展)和 LR。
- C 调用者无需关心底层寄存器操作,返回值自动放在 R0。
**实践建议
- 严格遵循 AAPCS:确保跨语言调用的稳定性。
- 现场保护优先:对可能修改的寄存器和 LR 入栈。
- 参数与返回值一致:确保 R0-R3 用于传递参数,R0 用于返回值。
- 函数小而专一:便于管理寄存器和堆栈,降低复杂性。
- 中断上下文安全:避免在中断中直接调用可能破坏调用者堆栈的汇编函数。
3.6 小结
本章全面构建了嵌入式系统的指令集基础与程序设计体系,首先深入阐述了 ARM 架构的两大核心指令集,ARM 指令集和Thumb 指令集,并解析了 ARM RISC 设计思想、Load/Store 架构及独特的条件执行机制。其次,章节详述了 ARM 处理器物理寄存器的组织结构、寻址方式,以及 CPSR/SPSR 在控制模式切换和异常处理中的核心作用。在程序开发实践中,覆盖了 ARM 汇编语言的伪操作和程序段组织,同时强调了嵌入式 C 语言的编码规范、模块化设计原则及 Git 版本控制的重要性。最后,讲解了 C 与汇编混合编程的关键,明确了 寄存器使用规范,确保了底层代码的高效、稳定和互操作性,是掌握飞腾派平台底层开发的关键指导。